#comparison #guide #deep-dive #integrations
REST vs GraphQL vs gRPC: Choosing the Right API Protocol for Your Project
· 8 min read
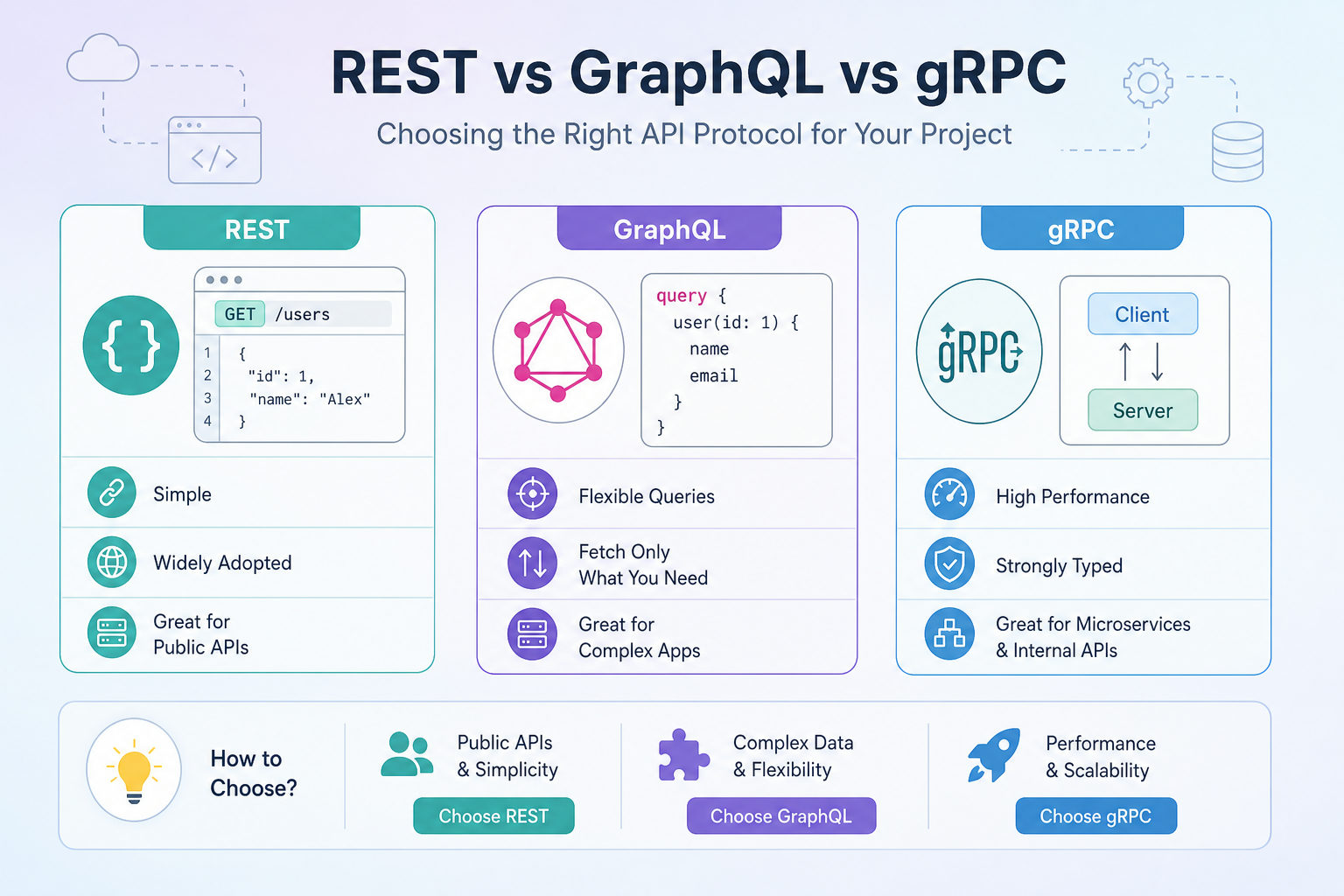
The protocol you choose shapes everything — from performance to developer experience. This guide cuts through the hype with practical trade-offs and real-world use cases for each approach.
The protocol you choose for your API shapes everything downstream: payload size, latency, tooling, client complexity, and how fast new developers can get productive. REST, GraphQL, and gRPC each solve real problems — and each introduces real trade-offs. This guide lays them out plainly so you can make the call that fits your project, not the one that fits the hype cycle. REST: The Universal Default REST (Representational State Transfer) is the baseline against which everything else is measured. It maps operations to HTTP methods ( , , , , ) and resources to URLs. Nearly every HTTP client, proxy, CDN, and monitoring tool understands it without extra configuration. Where REST wins: - Ubiquity. Any language, any runtime, any HTTP library can consume a REST API immediately. - Cacheability. responses are cacheable at the network edge — a CDN layer in front of a read-heavy API costs almost nothing to add. - Debuggability. You can inspect, replay, and share a REST request with nothing more than a URL and a header list. Paste a cURL command into a terminal and you're done. - Tooling depth. OpenAPI 3 has become a first-class contract format. Import an OpenAPI spec and your docs, mock server, and SDK generation follow automatically. Where REST struggles: - Over- and under-fetching. A endpoint returns every field whether the client needs two or twenty. Multiple related resources often require multiple round trips. - Versioning friction. There is no standard versioning mechanism. Teams reach for , path prefixes or header negotiation and then argue about which is correct. - Weak contracts. Without disciplined OpenAPI adoption, REST APIs drift. Field types change silently; undocumented fields appear and disappear. Best fit: Public APIs, mobile backends where cache headers matter, integrations with third-party consumers, and any team that values broad accessibility over optimisation. GraphQL: Precision Fetching for Complex Clients GraphQL replaces a collection of resource-oriented endpoints with a single endpoint that accepts a typed query language. Clients declare exactly what data they need; the server returns exactly that — nothing more. Where GraphQL wins: - No over-fetching. A mobile client on a 4G connection can request only the three fields it renders. A dashboard that needs deeply nested data gets it in one round trip. - Strongly typed schema. The schema is the contract. Introspection lets tools generate typed clients automatically, and deprecation is a first-class feature. - Rapid frontend iteration. Frontend teams can evolve their queries without backend changes as long as the schema supports it — a genuine productivity win for product-driven teams. - Subscriptions. Real-time updates via WebSocket are part of the spec, not an afterthought. Where GraphQL struggles: - Caching is hard. Because everything goes to a single endpoint, HTTP caching at the edge doesn't apply out of the box. You need persisted queries or a specialised CDN layer. - N+1 query risk. Naive resolvers can hammer a database. DataLoader patterns help, but they add complexity that REST simply doesn't impose. - Operational overhead. Rate-limiting, query depth limits, and cost analysis require custom middleware that REST teams get for free from any API gateway. - Learning curve for API producers. Designing a good schema — one that ages well and doesn't leak implementation details — is genuinely difficult. Best fit: Client-heavy products (SPAs, native apps) with multiple surfaces consuming the same data, internal APIs where the schema owner also controls all clients, and teams comfortable investing in backend resolver infrastructure. gRPC: High-Throughput Service-to-Service Communication gRPC is a Remote Procedure Call framework from Google built on HTTP/2 and Protocol Buffers (Protobuf). You define services and message shapes in a file; generates client and server stubs in your language of choice. Where gRPC wins: - Raw performance. Protobuf binary encoding is significantly smaller and faster to serialise than JSON. HTTP/2 multiplexing eliminates head-of-line blocking across concurrent calls. - Bidirectional streaming. Client streaming, server streaming, and full-duplex streaming are first-class — not bolted on. Low-latency data pipelines and real-time systems are natural fits. - Code generation as a contract. Generated stubs mean a type mismatch is a compile error , not a runtime surprise in production. - Deadline and cancellation propagation. gRPC carries context — including cancellation signals — across service boundaries automatically, which distributed tracing and timeout management depend on. Where gRPC struggles: - Browser support is limited. Standard gRPC relies on HTTP/2 trailers that browsers don't expose. gRPC-Web works around this but adds a translation proxy. - Observability requires investment. Binary frames are opaque to standard HTTP tooling. You need Protobuf-aware proxies and logging middleware to see what's flowing. - Schema evolution demands discipline. Field numbers in files are permanent. A careless change breaks all existing serialised messages. - Steeper onboarding. Developers comfortable with and JSON need to learn a new toolchain before they can send their first request. Best fit: Internal microservice meshes where both sides of the connection are under your control, latency-sensitive workloads, and streaming data use cases like telemetry or event pipelines. Side-by-Side: The Key Dimensions | Dimension | REST | GraphQL | gRPC | |---|---|---|---| | Transport | HTTP/1.1 or HTTP/2 | HTTP/1.1 or HTTP/2 | HTTP/2 only | | Payload format | JSON (typically) | JSON | Protobuf (binary) | | Caching | Native HTTP caching | Complex | Not applicable | | Streaming | Limited (SSE) | Subscriptions | Full bidirectional | | Browser support | ✓ | ✓ | Partial (gRPC-Web) | | Schema / contract | Optional (OpenAPI) | Built-in | Built-in (.proto) | | Performance | Good | Good | Excellent | | Onboarding friction | Low | Medium | High | Mixing Protocols in Practice Most mature systems don't pick one protocol and enforce it everywhere. A common pattern: 1. Public-facing API — REST over HTTPS with an OpenAPI contract. Third-party developers, mobile clients, and webhook consumers all know how to work with it. 2. Client-to-BFF (Backend for Frontend) — GraphQL between the browser or native app and an aggregation layer. The frontend team owns the queries; the BFF owns the schema. 3. Internal service mesh — gRPC between the microservices the BFF fans out to. Low latency, strong typing, and efficient serialisation where browser compatibility is irrelevant. The discipline here is resisting the urge to use your favourite protocol everywhere. The right tool for each layer of the stack produces a system that's easier to scale, debug, and hand to the next team. Working with All Three in APIKumo Regardless of which protocol you choose, you can design, test, and document it from a single workspace. REST and GraphQL are first-class citizens in the request editor. The body editor supports a dedicated GraphQL mode with syntax highlighting alongside JSON, XML, and the other formats you'd expect. Bearer, Basic, and API-key auth are built in, and substitution means your and resolve at send-time — no secrets baked into saved requests. With bound in your environment, switching between Local, Staging, and Production is a single click. For gRPC workflows , you can use APIKumo to test and document the HTTP/1.1 REST or gRPC-Web endpoints that sit in front of your Protobuf services, generate the full OpenAPI export, and publish it to a public docs site at — complete with a Try-it panel and an MCP endpoint so AI agents can read and call your API surface directly. Post-processors let you chain requests regardless of protocol: extract a token from an auth response, store it as , and have every subsequent request in the collection pick it up automatically. How to Decide Run through these questions before committing: - Who are your consumers? External developers and third parties push strongly toward REST. Internal teams with generated clients can absorb gRPC's tooling cost. - How important is edge caching? If your API is read-heavy and you want CDN offload with zero extra work, REST is still the only clear answer. - How varied are your clients' data needs? If a mobile app, a dashboard, and a data export tool all hit the same data, GraphQL's precision fetching pays for itself quickly. - Is latency between services a bottleneck? If profiling shows serialisation or connection overhead between microservices, gRPC's binary transport is a genuine lever. - What's your team's operational maturity? GraphQL's resolver complexity and gRPC's observability requirements both demand investment. A small team shipping fast may be better served by a well-documented REST API and a clear OpenAPI contract. Wrapping Up REST remains the safest default for anything that faces the public internet — not because it's technically superior, but because its constraints are well-understood and its tooling is everywhere. GraphQL earns its complexity budget when you have multiple surfaces with genuinely divergent data needs. gRPC pays off in high-throughput internal service meshes where you control both ends of the wire. The most pragmatic systems use all three in the right places. Define the boundaries clearly, document each interface with the same rigour you'd apply to public APIs, and choose based on the concrete constraints of your project — not on what's trending.